
Tự động hoá thiết kế & tối ưu harness bằng Autoagent
Autoagent giúp liên tục sinh, tối ưu và bảo trì các task-specific agent trên quy mô toàn công ty.
Với những ai đang xây dựng hoặc vận hành hệ thống agent, một trong những phần tốn công nhất không phải là viết code, mà là tinh chỉnh harness – tổ hợp prompt, tool và orchestration logic – sao cho phù hợp với từng domain cụ thể. AutoAgent là một hệ thống được thiết kế để tự động hóa phần này.
Vấn đề mà AutoAgent nhắm tới
Mỗi domain (CSKH, vận hành nội bộ, phân tích log, tài chính…) đòi hỏi một harness riêng. Người thiết kế vừa cần hiểu domain, vừa cần hiểu hành vi của mô hình ngôn ngữ – và hầu hết các team không có đủ bandwidth để tune hàng trăm harness như vậy.
AutoAgent tiếp cận bài toán này bằng cách cho phép domain expert chỉ cần định nghĩa tiêu chí thành công thông qua bộ eval/benchmark. Phần còn lại – thử nghiệm, sửa harness, phân tích failure trace – do một meta-agent đảm nhận.
Ở góc độ tổ chức, AutoAgent được định vị như một lớp infrastructure cho agent fleet: liên tục sinh, tối ưu và bảo trì các task-specific agent trên quy mô toàn công ty.
Cách AutoAgent hoạt động
Kiến trúc cơ bản gồm bốn thành phần: một task agent (ban đầu chỉ có bash tool), file program.md để định hướng cho meta-agent, agent.py là implementation của task agent, và một Harbor adapter kết nối vào benchmark/eval.
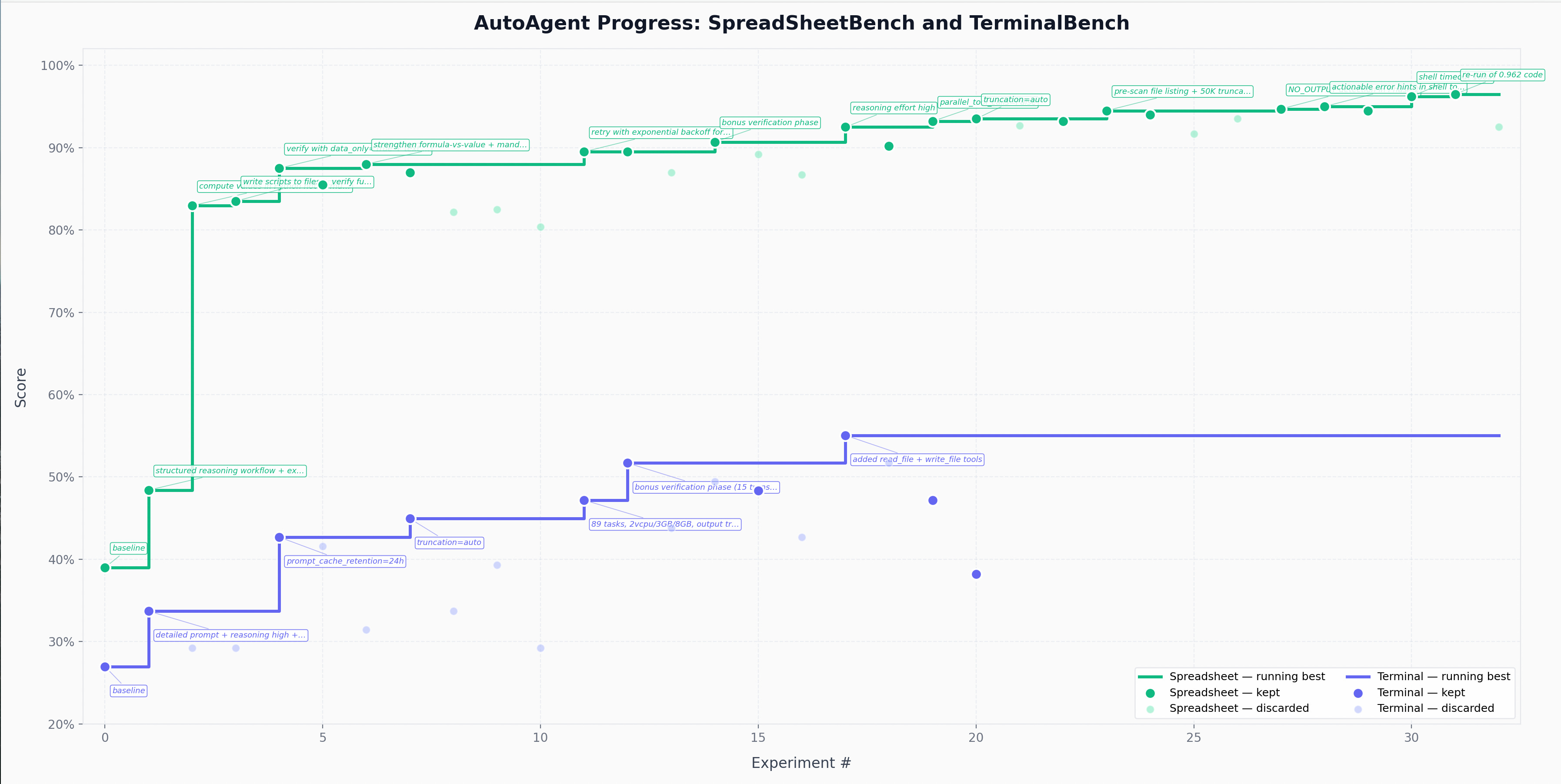
Meta-agent chạy một vòng lặp: chỉnh harness → cho task agent chạy trên task → đo performance → đọc failure traces → giữ thay đổi tốt, revert thay đổi xấu → lặp lại. Quá trình này được scale bằng cách chạy song song hàng ngàn sandbox. Theo nhóm tác giả, sau khoảng 24 giờ, hệ thống có thể tự khám phá được tooling, verification loop và orchestration logic phù hợp cho domain đích.
“Model empathy” – meta-agent hiểu task agent như thế nào
Một quan sát đáng chú ý từ nhóm nghiên cứu: meta-agent có xu hướng thiết kế harness hiệu quả hơn con người trong một số trường hợp, do nó đọc được reasoning trace của task agent và có sẵn hiểu biết về giới hạn, thiên hướng, kiểu lỗi thường gặp của chính mô hình đó.

Thực nghiệm cho thấy cặp cùng model (ví dụ Claude meta-agent + Claude task agent) cho kết quả tốt hơn cặp khác model (Claude meta-agent + GPT task agent). Giải thích được đưa ra là meta-agent viết harness đúng “ngôn ngữ nội tâm” của model hơn khi cả hai cùng kiến trúc.
Một số hành vi emergent
Trong quá trình chạy, meta-agent thể hiện một số hành vi tự phát:
Spot checking: khi chỉ thay đổi nhỏ, meta-agent không chạy toàn bộ test suite mà chọn một vài task để kiểm tra nhanh.
Forced verification loops: tự tạo bước self-check và validator format, tách riêng budget cho việc verify/correct output khỏi budget làm task chính.
Viết tests: meta-agent hướng task agent tự sinh unit test cho từng task.
Progressive disclosure: khi context quá lớn, agent tự ghi ra file rồi tham chiếu lại, thay vì nhồi vào một context duy nhất.
Orchestration logic: tự tạo thêm sub-agent và flow riêng khi domain yêu cầu chia nhỏ nhiệm vụ.
Một vài kịch bản áp dụng
Xử lý ticket nội bộ (Ops/CS): Chuẩn bị tập ticket thật hoặc synthetic kèm expected resolution làm eval. Implement task agent với các tool cơ bản (query DB, gọi internal API). Định nghĩa tiêu chí thành công (tỉ lệ giải đúng, SLA, không gây side-effect). AutoAgent sẽ tối ưu harness dựa trên pattern ticket thực tế của tổ chức.
Phân tích log & incident (Data/Platform): Lấy bộ incident thật với timeline, log và RCA đúng làm ground truth. Cho task agent quyền truy cập log store, metric API, runbook repo. AutoAgent sẽ tự tìm cách tổ chức tool call phù hợp – khi nào đọc log, khi nào tra runbook, khi nào hỏi lại context.
Tự động hóa workflow nhỏ: Hầu hết công ty có hàng trăm workflow lặp lại (chuẩn hóa dữ liệu, sinh báo cáo tuần, sync giữa hai hệ thống…). Thay vì mỗi team tự build script riêng, có thể chuẩn hóa cách xây eval rồi dùng AutoAgent sinh và tune harness cho từng workflow, dần hình thành một agent fleet phụ trách các tác vụ lặp.
Kết quả benchmark
Trên các benchmark công khai, AutoAgent đạt 96.5% trên SpreadsheetBench và 55.1% GPT-5 score trên TerminalBench, hiện đứng đầu leaderboard – trong khi các entry khác đều do con người thiết kế harness thủ công.
Chúng ta nên làm gì?
Kết quả trên cho thấy một hướng tiếp cận đáng cân nhắc: thay vì đầu tư nặng vào việc thiết kế thủ công từng agent, có thể chuyển trọng tâm sang meta-layer – xây dựng tooling và eval tốt để một meta-agent liên tục sinh và tối ưu các agent nhỏ, gắn vào workflow cụ thể của tổ chức.